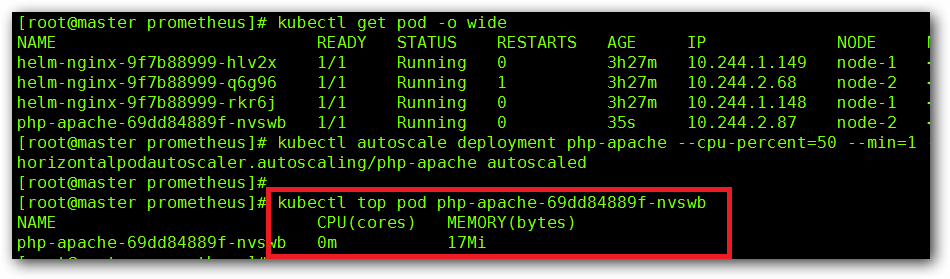
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 ReplicaSet、Deployment 或者中的 Pod 数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| cat hpa-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-web
spec:
selector:
matchLabels:
app: hpa-web
replicas: 1
template:
metadata:
labels:
app: hpa-web
spec:
containers:
- name: hpa-web
image: gcr.io/google_containers/hpa-example
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: hpa-web
spec:
type: ClusterIP
selector:
app: hpa-web
ports:
- name: http
port: 80
targetPort: 80
|

创建 HPA 控制器 - 相关算法的详情请参阅这篇文档:http://git.k8s.io/community/contributors/design-proposals/horizontal-pod-autoscaler.md#autoscaling-algorithm
1
| kubectl autoscale deployment hpa-web --cpu-percent=50 --min=1 --max=10
|
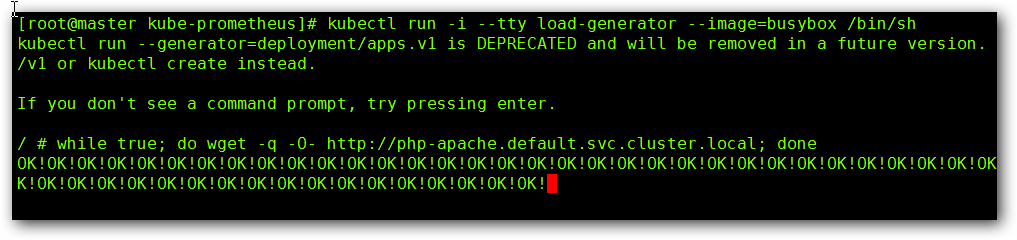
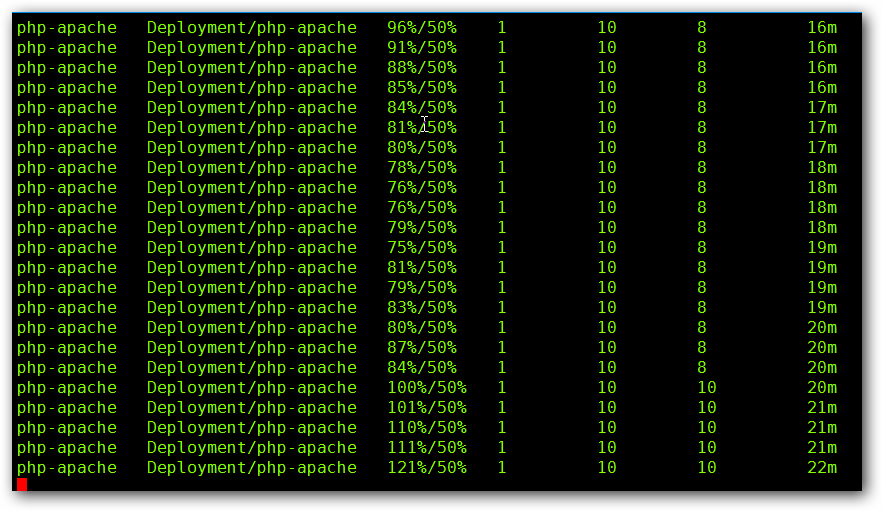
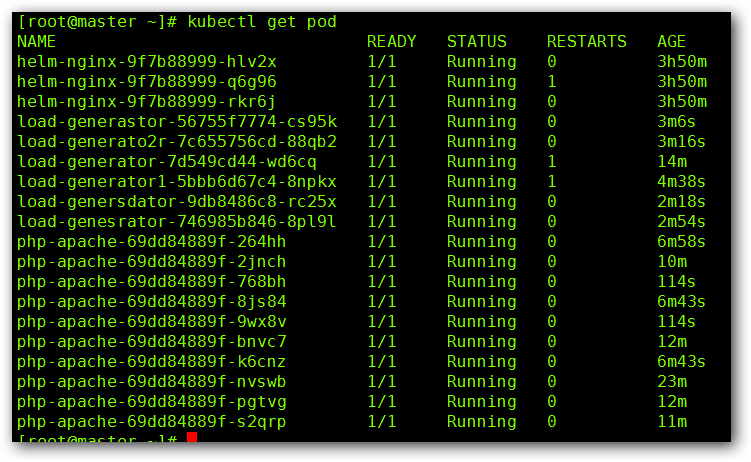
增加负载,查看负载节点数目
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| 两种方式:
1.命令行创建:
创建测试POD:
kubectl run -i --tty test --image=busybox --image-pull-policy='IfNotPresent' /bin/sh
执行命令:
while true; do wget -q -O- http://hpa-web.default.svc.cluster.local; done
2.副本控制器创建:
cat test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ceshi
spec:
selector:
matchLabels:
app: ceshi
replicas: 1
template:
metadata:
labels:
app: ceshi
spec:
containers:
- name: ceshi
image: docker.io/busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'while true; do wget -q -O- http://hpa-web.default.svc.cluster.local; done']
|
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup
默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过resources 的 requests 和 limits 来实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| spec:
containers:
- image: xxxx
imagePullPolicy: Always
name: auth
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: 250m
memory: 250Mi
|
requests 要分配的资源,limits 为最高请求的资源值。可以简单理解为初始值和最大值
资源限制 - 名称空间
1、计算资源配额
1
2
3
4
5
6
7
8
9
10
11
12
| apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: test
spec:
hard:
pods: "20"
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi
|
2、配置对象数量配额限制
1
2
3
4
5
6
7
8
9
10
11
12
| apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: test
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
ReplicaSet: "20"
secrets: "10"
services: "10"
|
3、配置 CPU 和 内存 LimitRange
1
2
3
4
5
6
7
8
9
10
11
12
13
| apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 50Gi
cpu: 5
defaultRequest:
memory: 1Gi
cpu: 1
type: Container
|
default 即 limit 的值
defaultRequest 即 request 的值